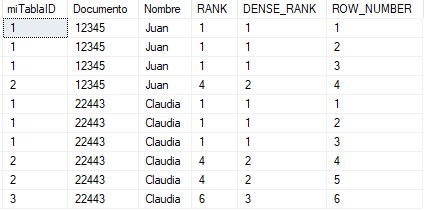
Método 5
Este quinto método, al igual que los dos anteriores, utiliza un campo para ordenar y otro como partición. Para una serie de registros duplicados, estos aparecerán con un valor que les identifique, por ejemplo: si tengo dos registros iguales, uno de ellos tomará el valor 1 y el otro el valor 2.
La sintaxis es la siguiente:
ROW_NUMBER ( ) OVER ( [ PARTITION BY value_expression , ... [ n ] ] order_by_clause )
Con la siguiente sentencia podremos conocer que registros tenemos repetidos en nuestra tabla:

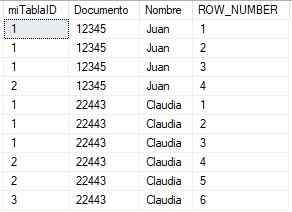
El registro con valor 22443 en el campo “Documento” tiene 6 registros iguales y cada uno de ellos toma un valor distinto.
A continuación, en la siguiente tabla se hace una comparativa entre los métodos 3, 4 y 5 para, de una forma más visual, comprender el funcionamiento de cada uno de ellos: