La llamada más temida que puede recibir un DBA es la siguiente: "¡Todo en la aplicación va lento! ARREGLALO, pero YA!". En muchos casos, la base de datos es una de las culpables del bajo rendimiento del código heredado. Los usuarios – CON TODA LA RAZÓN – se quejan de la lentitud de una aplicación. Pasado el primer momento de pánico (te echas a temblar, sudores fríos, etc.) porque lleva toda la vida funcionando, siquiera la hiciste tú… ¿por dónde empezar? Te damos las claves y una aproximación rápida y aplicada para que todo vuelva a ser felicidad y alegría
Hay infinidad de artículos a propósito de cómo optimizar el rendimiento de la base de datos, pero a veces LO MEJOR ES ENEMIGO DE LO BUENO. La actividad de refactorización de código es ardua, y no está al alcance de cualquiera. Y por encima de todo supone gran cantidad de tiempo. Otros usuarios opinan que el mejor “fine tunning” es comprar más hardware; es más barato subir los gigas en el servidor que el precio hora de un buen DBA.
En nuestra opinión una opción intermedia es aproximarse al problema a través de la estrategia DIVIDE y VENCERÁS. A continuación, se proponemos nuestra propia metodología para una aproximación rápida a su resolución.
Los pasos:
- Identifica la sentencia a mejorar
- Activar las estadísticas para establecer la línea base
- Analizar las trazas y utilizar propuestas de mejora propuestas por el propio SGBDR
- Volver a medir para comprobar la posible mejora
Detalles:
En primer lugar, identifica la sentencia a optimizar o procedimiento almacenado en el que poner el foco.
En segundo lugar, hay que activar el proceso de monitorización de las estadísticas. Podemos hacerlo de forma permanente o bien puntual por sesión
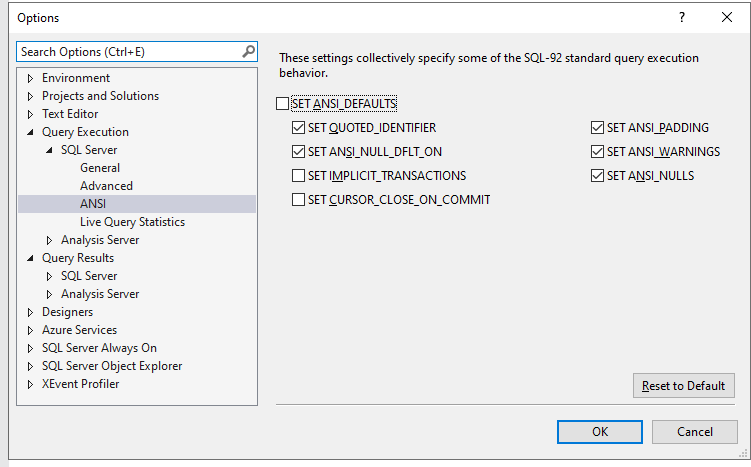
En su defecto para hacerlo por sesión ejecutando: SET STATISTICS TIME, IO ON;
En tercer lugar, tomaremos las trazas tras ejecutar la sentencia a mejorar
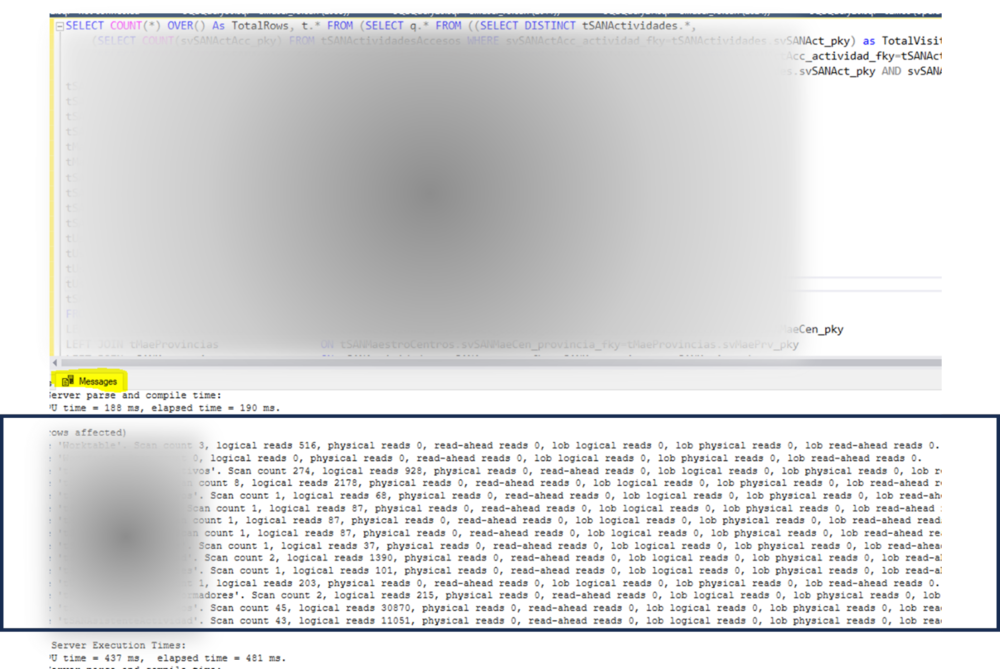
A modo de complemento podemos utilizar la página http://statisticsparser.com/ para mostrar las estadísticas de una forma más legible
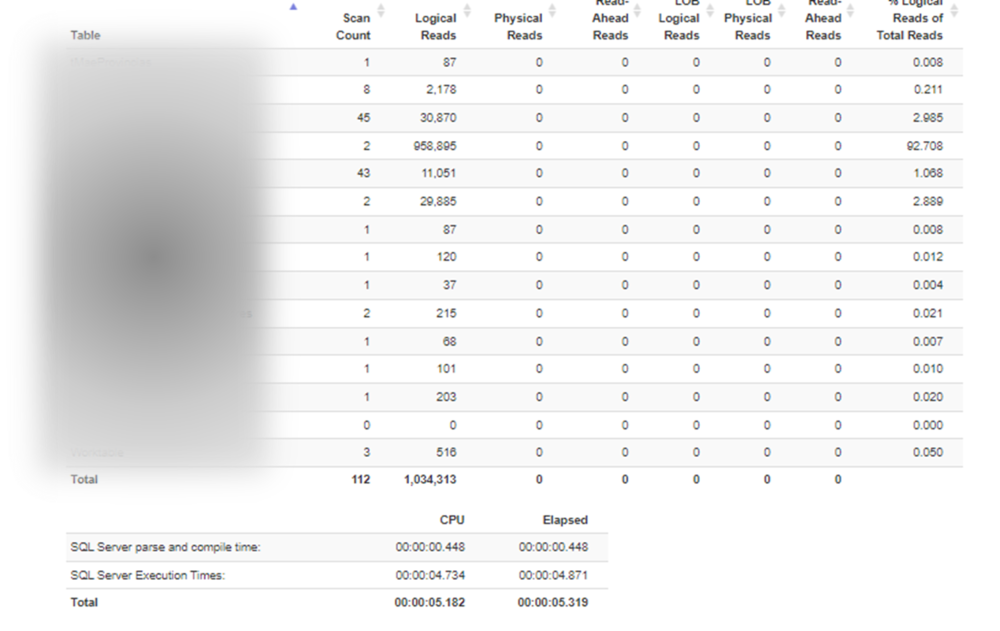
En este caso se puede ver en la imagen la tabla que acumula el mayor número de accesos. Es importante repetir el proceso y no tomar las estadísticas de la primera ejecución, para que los datos ya estén en memoria y los planes de ejecución hayan aplicado.
A partir de ahí bien vamos a la tabla para ver la estructura de índices y/o relaciones o utilizamos los servicios de “recomendación” de mejoras. En este ya nos está haciendo una propuesta, que habrá que valorar cuidadosamente
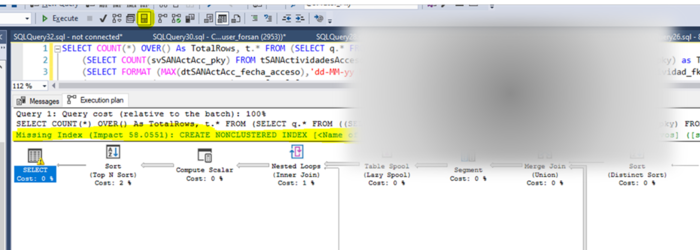
Una vez aplicado el cambio (UNO CADA VEZ), volveríamos a ejecutar la sentencia para ver el efecto. En este caso concreto, tras aplicar el cambio propuesto, las estadísticas pasan a ser las siguientes
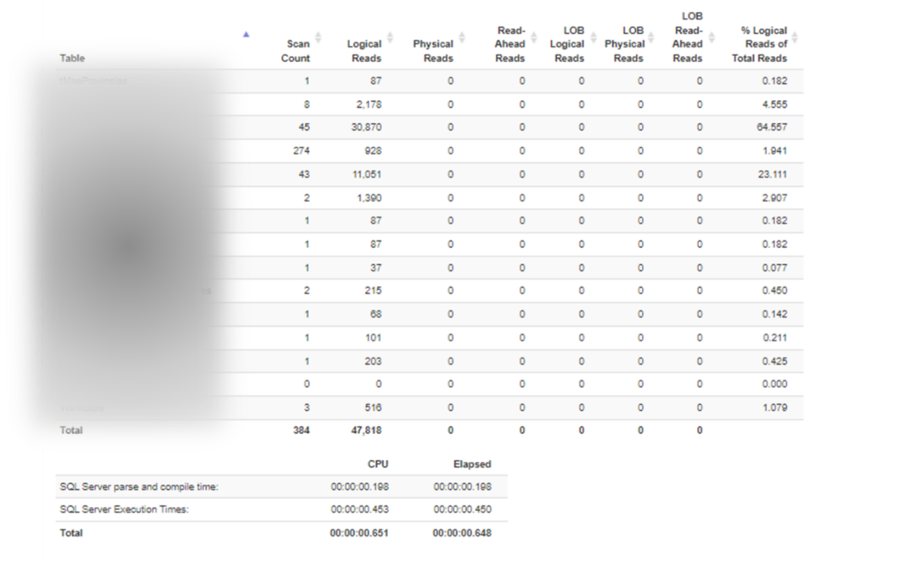
Como se puede ver el número de lecturas se ha reducido de más de 1 Millón a algo menos de 50k.
Bien en este caso con no mucho esfuerzo se ha podido optimizar de forma notable el tiempo de respuesta y no ha sido necesario comprar más hardware 😊
A por la siguiente…
Algunas referencias de interés:
Refactoring Legacy T-SQL for Improved Performance: Modern Practices for SQL Server Applications. Lisa Bohm.
SQL Server Index Tutorial Overview
An Introduction to SQL Server Indexes: Stairway to SQL Server Indexes